
- 커널은 하드웨어을 관리해야 됨
- 또한 프로그램들이 잘 돌아갈 수 있도록 잘 받쳐줘야 함

- 하드웨어 관리를 위해 metadata를 가지는 내부적인 자료구조?를 가지고 있음
- ex) disk 같은 경우엔 어떤 섹터가 놀고 있는지에 대한 정보
- 프로세스 관리를 위한 데이터 구조인 PCB(Process Control Block)도 있음
PCB(Process Control Block)

- PCB가 가져야 하는 metadata의 집합
- 프로그램을 돌리다 예를 들어 disk에 대한 I/O 작업을 해달라 하면 disk wait queue에 들어가고 I/O가 끝났을 때 상태를 표시하기 위한 Status가 있음
- I/O가 끝나서 CPU의 처리가 필요하면 ready queue라는 리스트에 들어감
- process가 I/O 작업이 필요하면 일단 I/O를 하고 나중에 CPU가 처리함
- process 간 context switching 필요함
- context switching을 위해 꽤 많은 정보들을 PCB에 저장해야 됨
- directory 같은것도 그래서 PCB에 있음

- disk I/O queue와 ready queue는 저런 식으로 생겨있음
- 즉 CPU 처리는 queue에 달려있는 순서대로 처리하고 disk I/O도 queue에 달려있는대로 처리함
- disk 같은 곳에서 데이터 전달해주는 작업을 CPU 대신 처리해줘서 효율적으로 처리할 수 있게 해주는게 DMA
Creating a child process

- 부팅 하면 커널이 올라오고 터미널 켜지면 커널 밑에 쉘을 만들어줌
- shell에서 또 실행시키면 shell의 child가 됨
- child process 생성 순서
1) PCB 할당이후 parent's PCB를 copy -> 상속, 자원 공유
- 같은 terminal
- 같은 working directory
-> 결국은 실행 환경과 리소스 맞추기
2) 메모리로 가서 확인해서 남는 공간에 child가 들어갈 메모리 할당하고 parent's image 복사
3) image를 disk에서 가져와서 바꿈
4) child process ready list 달기
- 아직은 parent가 CPU 점유 중이라서 queue에 달아놓기
- fork, exec syscall
- fork는 step 1, 2 -> PCB, image가 parent랑 똑같은 process 만들어줌
- exec는 step 3, 4 -> image 읽고 load, ready list 달기 -> 실행
- 결국은 process create가 fork exec 2 steps로 이루어짐

- pid 제외하고 똑같음

- 당연한 얘기

- fork는 호출하면 리턴이 두개의 프로세스한테 감
- OS가 parent process와 child process한테 각각 다른 return 값을 줌
- PCB와 image가 복사되었으니 main의 처음부터가 아니라 save cpu state vector에 따라서 Program Counter가 가리키는 곳부터 실행함
- pid 가지고 parent랑 child를 가리는 것을 확인할 수 있음

- 결과
- 강의에서 설명하시는 교수님은 I am Parent 출력문이 else 뒤에 있어야 한다고 말씀하시는데 fork로 child process 생성했을 때 PC가 if문 부분을 가리켜서 printf가 앞에 위치해도 상관없는거 같다


- 돌려보면 똑같이 나옴
- fork 성공하면 child한테 0 return 되고 parent 한테는 child의 pid가 return 됨

- fork 하고 exec syscall로 /bin/date를 실행시키는 예제
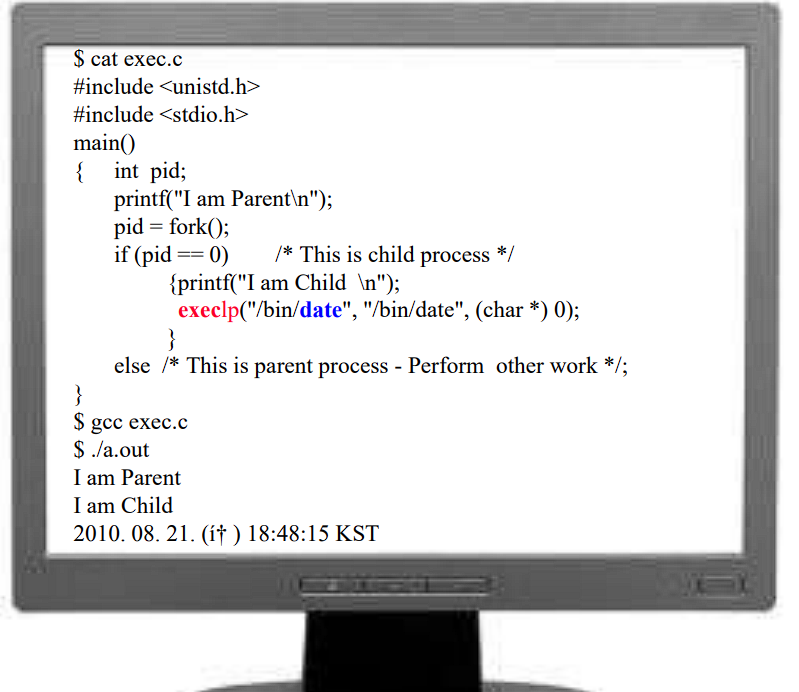
- 결과

- 아주 약간 수정했는데 기능은 동일한 코드임

- 똑같이 나옴
|
1
|
int execlp( const char *file, const char *arg, ...);
|
cs |
- execlp인데 argv[0]에 경로 들어가고 가변 인자 함수 끝을 NULL로 넣어줘서 저렇게 넣어줬음
- (char *)0 넣어도 됨 어차피 둘 다 Null pointer

- wait가 호출되면 kernel은 호출한 process한테서 CPU를 뺏음
- 그리고 kernel이 child process 실행
- child process가 terminate 되면 kernel이 parent process를 깨움
- kernel이 parent process를 ready queue에다 넣음

- 간단한 예제
- wait()가 parent sleep 시키고 child 끝나면 parent가 resume
- wait 없으면 child parent 둘 다 같이 실행됨


- 보면 child가 terminate 되고 parent가 처리되는 것을 확인 가능함

- exit syscall은 process 끝낼 때 씀

- gef로 열어보고 exit_group이라는 thread를 terminate 시켜주는 syscall에 breakpoint를 걸었고 exit에도 걸었음

- trace대로 호출됨
- __GI_exit에서 __run_exit_handlers가 호출되고 __GI__exit에서 최종 종료됨
- exit_group syscall이 쓰이고 종료됨
- exit syscall이 쓰이지 않는 자세한 이유는 https://www.linuxquestions.org/questions/programming-9/about-exit_group-call-741881/
about exit_group call
I am using exit_group in my program. when I compiled the program, it is giving an undefined reference to exit_group. I didn't get why it is giving undefined reference
www.linuxquestions.org
- glibc 2.3 이전에는 _exit() wrapper function이 _exit을 썼었지만 glibc 2.3 이후로 process의 모든 threads를 terminate 하려고 wrapper function이 exit_group을 부른다고 함
- 옛날 강의라서 exit으로 설명한 듯

- 나온 syscall 정리
Context Switching

- context switching이 어떻게 일어나는지 순서

- user mode, kernel mode 왔다 갔다 함

- 순서
1) P1이 wait 하면 PCB에 cpu state vector가 저장됨
2) kernel이 P2를 돌리기로 선택함
3) kernel이 kernel 영역의 data structure 뒤져서 P2의 PCB를 찾음
4) CPU 상태 복구 (save cpu state vector)
5) P2 돌리기

- schedule이라는 kernel의 내부 함수가 있음
- read, write 같은 I/O syscall이나 exit 같은 syscall들이 호출함
- kernel 밖에서 syscall로 호출 못해서 internal function이라고 부름
- 다음으로 돌릴 프로세스를 고르고 context_switch를 호출함
- context_switch는 retiring process의 PCB에 current CPU state vector를 저장하고 arising process의 PCB를 load한뒤 PC를 보고 잘 실행시킴


- 지금까지 한 거 총정리
What constitutes a Process "Context"

- 만약 초기값을 갖고 있다면 binary에 초기값을 넣어야 되는데 - data
- 초기화되지 않은 global variable이 필요하다면 run time에 memory 할당을 해도 됨 - bss
- 즉 굳이 파일에 공간을 만들어서 디스크 공간낭비를 하지말고, 그냥 런타임에 할당하자는 논리
- user space, kernel space, hw 통틀어서 context라고 하는 것 같다
- 그냥 그때 상황? 정도로 이해하면 될듯하다
"Daemon" (or "Server") Process

- server임
- 대부분 비슷한 알고리즘을 가지고 있음
- sleep 하다가 요청오면 서비스해줌


- process state를 자세히 출력해보면 이렇게 나옴

- 대부분 뒤에 d가 붙음
- daemon 이라서
Linux PCB consists of 6 structs

- Linux의 PCB는 6개 structs로 나뉨
- task basic info는 말 그대로 basic info
- files는 open 한 파일의 정보
- fs는 access 하고 있는 file system
- tty는 사용 중인 terminal
- mm은 process 사용중인 main memory
- signals는 signals

- task_struct가 linux PCB임
- 6개 struct로 나뉜 것을 볼 수 있음
Why 6 structs?

- 기본적으로 child process를 만들면 PCB copy에서 1차 overhead가 있고 image 복사에 2차 overhead가 발생
- heavy-weight creation에서는 모든 것을 복사함
- light-weight creation에서는 각각의 struct들을 pointing 하는 task_struct를 만들어서 생성 overhead를 줄임
- 즉 그냥 parent 껄 그대로 pointing 하기만 해서 굳이 모든 구조체를 다시 만들필요가 없어짐

- child를 process로 만들면 image도 복사해야 되고 pcb에서도 다 복사해야됨 -> read/write가 너무 많음

- 그래서 나온 게 child를 thread로 만드는 것
- Task basic info만 copy
- 즉 나머지는 그냥 parent껄 갖다 씀

- Linux thread는 그래서 Light Weight Process라고도 부름
- 이걸 해주는 건 fork가 아닌 clone

- clone syscall은 5개의 flags를 가짐
- 5개의 binary bit 중에 1 인건 copy 대상이 됨
- fork처럼 heavy-weight creation 하고 싶으면 11111 주면 됨
- Linux에서의 thread는 00000을 줬을 때

- manual 보면 child process가 execution context를 calling process와 공유할 수 있다고 적혀있는 것을 확인할 수 있음
- 주목적은 thread 만드는 데 사용됨
- parameter로 function pointer, stack pointer 같은 것을 받음
Child creation in old UNIX Code

- Parent가 chlid create 할 때 PCB copy 할 때 overhead가 있고, image copy할때 overhead가 존재함
- 사실 image를 copy 하는데 드는 overhead가 대체로 많음
- fork로 parent가 복사되기를 원하는 사람도 있을 수 있지만 비효율적일 수 있음
- ls를 예로 들면 ls를 쳤을 때 child로 shell을 복사하고 그 쉘 위에 ls로 overwrite 하는 것은 비효율적임
- 그래서 엔지니어들은 child가 parent의 image를 가리키는 page mapping table만 복사하면 더 효율적으로 처리할 수 있다고 생각했음
- 이 page mapping table 가지고 read 하고 execute 함
- parent가 page를 modify 하거나 child가 modify 하게 되면 그때 extra copy를 만들게 함
- 즉 COW(Copy On Write)는 기본적으로 부모 페이지 테이블을 줘서 페이지들 공유 시켜놓도록하고, 프로세스가 쓰면 그때그때 extra copy를 만드는것
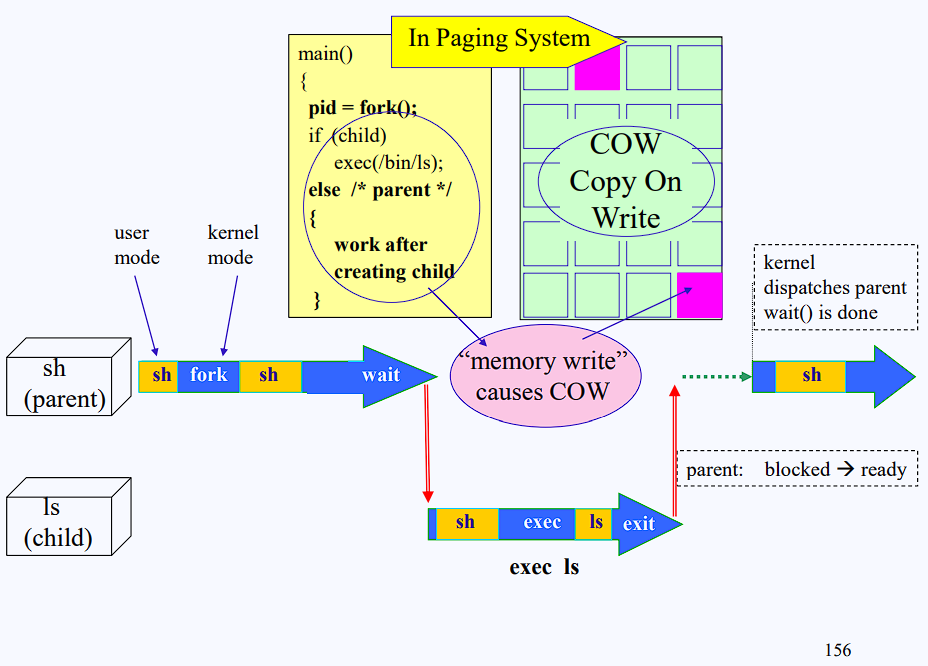
- parent가 fork로 child를 만들고 wait로 child 한테 cpu를 넘겨줌
- ls 실행되고 return 해서 다시 돌아옴
- 문제는 wait를 안 하고 fork 하고 parent가 memory access 할 때 발생함
- parent가 memory access 해서 write 하면 Copy On Write를 하는데 대부분 child는 cpu 받자마자 exec으로 싹 다 갈아엎어서 쓸데없는 copy overhead가 생김
- 낭비임

- fork의 return 이후의 memory write는 COW page faults를 일으킴
- 그리고 그 COW pages는 거의 안 쓰임

- 그래서 Linux에서는 child의 priority를 높임
- fork가 return 되고 ready list에서 priority가 더 높은 child를 scheduler가 보고 실행시키게 됨
- 이렇게 하면 COW page fault 없앨 수 있음

- 즉 정리하자면, 어차피 child는 exec으로 갈아탈 가능성이 높은데, 굳이 parent를 먼저 돌려서 COW fault를 만들 이유가 존재하냐는 이야기
- child를 먼저 돌렸을때 exec으로 갈아타면, 어차피 부모의 copy는 필요없어짐
- 그러면 parent에게 통해 signal이 보내지는데, 그러면 mm_release를 통해 COW가 꺼짐
- child가 exec 때문에 안 갈아엎어져도 그냥 child가 먼저하면 COW 정상적으로 할 수 있음
Kernel Thread

- memory resident 한 kernel의 light-weight child가 thread라고 볼 수 있음
- clone syscall로 만들어짐
- kernel code만 돌림
- kernel process의 address space에 접근함
- 대부분은 daemon임

- 4개의 CPU가 돌아가고 있음
- clone으로 만든 kernel thread가 CPU에 할당됨
- kernel thread들은 Task basic info만 복사해오고 나머지는 kernel process 꺼 공유함
- CPU state vector만 가져와서 각자의 PC, SP 값을 가질 수 있음
- 그래서 각자의 kernel stack을 가지며 다른 함수의 호출이 가능

- running 하다 I/O 때문에 CPU 뺏긴걸 waiting이나 sleeping 혹은 blocked 라고 부름
- wait는 두 개로 나뉘는데 signal 왔을때 respond 여부에 따라 두개로 나뉨
- I/O가 끝나면 ready list join 해야 됨
- 그때 그 상태를 ready
- 자기 차례 오면 dispatch 되고 running
- 끝나고 exit 하고 PCB만 남은 상태를 zombie state라고 함
- PCB를 남기는 이유는 만약 child process가 잘 돌고 끝난 뒤 parent가 그걸 확인해야 돼서
- parent가 나중에 zombie state의 child의 PCB를 말소시킴
'OS, Kernel' 카테고리의 다른 글
| Kern Koh Kernel of Linux Interrupt 정리 (0) | 2022.08.06 |
|---|---|
| Kern Koh Kernel of Linux Scheduling 정리 (0) | 2022.07.20 |
| Kern Koh Kernel of Linux System Call 정리 (0) | 2022.07.18 |
| Kern Koh Kernel of Linux Introduction 정리 (0) | 2022.07.18 |