Why protection is necessary in Linux
Linux :
- Multi-user
- Protection - Yes
- Resource - minimize
- Text mode CUI(Character User Interface)
Windows
- Single-user
- Protection - Little
- Resource - user them all
- Windows, GUI(Graphical User Interface)
- Shows everything
ex) History, State, Command, Option...
참고) Windows도 XP 이후부턴 multi-user Operating System이라고 한다.
Resource Usage & OS User Interface
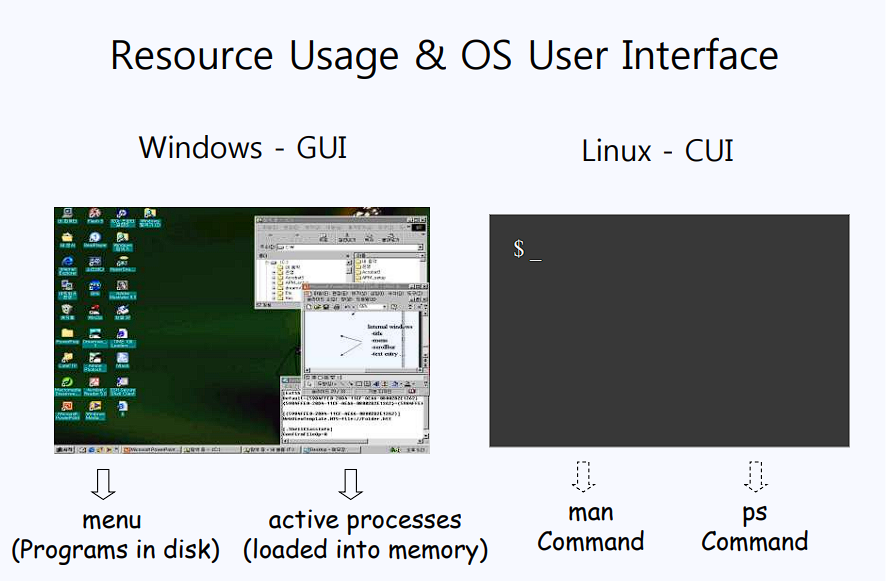
- Windows에선 programs를 확인 가능하고, active process들도 확인 가능하다. 자원도 많이 먹는다.
- Linux에선 ps command를 통해서 active process를 확인할 수 있고, man으로 menu를 확인할 수 있다. $_ 만 출력하면 되니 2 bytes 정도의 적은 자원을 먹는다.
Multi-user system -- Protection
- 만약 process P1이 bug나 virus라서 P2의 정보에 illegal access가 가능해서 read/write가 가능하다면 문제가 발생함

- illegal access를 그때그때 잡아내는 데에는 한계가 존재해서 방지해야 함

- 그래서 나온게 protection임
How does protection work

- Kernel 제외 모든 I/O instruction들은 허용되지 않음
- System call을 통해 kernel에게 I/O instruction의 처리를 요청
- kernel이 access를 검증하고 I/O functions를 통해 I/O 작업을 처리해줌

- system call의 동작을 도와주기 위해서 cpu hardware에 하나의 binary bit를 도입함
- 도입한 binary bit를 여기선 mode bit이라고 부름

- instruction을 가져와서 opcode를 보고 CPU가 작업을 처리하게 됨

- mode bit가 1이 돼서 kernel mode를 가리키면 모든 memory에 접근할 수 있고, 모든 instruction들을 사용가능함
- mode bit이 0이라 User mode를 가리키면 모든 instruction을 할 수 없고 자신의 local address space만 접근할 수 있음
- 결론적으로 privileged op-code 수행을 mode bit에 따라 제한받는다고 볼 수 있음
- privileged op-code는 I/O instruction이나 special-register access나 어떤 것이든 다른 것을 해칠 수 있는 op-code를 의미함

Memory address 검증
- CPU의 instruction cycle에서 CPU가 instruction fetch를 하기 위해서는 memory에 접근을 해야 됨
- operands 가져올때도 memory 접근은 필수

- 이렇게 CPU가 계속 memory에 address로 access 할 때, cpu와 memory 사이 memory bus에 있는 MMU(Memory Management Unit)가 mode bit으로 kernel mode인지 user mode인지 확인함
- User mode일 때
1) MMU가 CPU가 user mode인 것을 확인했다면 address를 보고 그 프로세스의 address space range안에 들어가는지 확인함
2) address space range 벗어나면 거부시킴
- kernel mode일 때
1) kernel 이 돌아가고 있다면 제약이 없음
참고) MMU는 logical address를 physical address로 바꿔주는 역할을 주로 함
Execute단에서의 검증
- execute 할 때 op-code도 검증함
- User mode일 때
1) privileged op-code 라면 실행 못 시키게 함
2) privileged op-code가 아니면 그냥 실행시킴
- kernel mode일 때
1) op-code가 뭐가 되던 상관없음
2) 제한 없음
얻을 수 있는 효과 : illegal access 차단 가능
How do programs handling I/O

- Source: I/O statement를 가지고 있음
- Binary: compiler가 I/O statement를 없애고 parameter를 준비하고 execute chmodk(change mode kernel) instruction 같은 것으로 바꿈

- Binary가 실행되는 Run time
- program이 chmodk를 실행함
- chmodk는 privileged instruction임
- CPU는 user-mode 상태에서 더 이상 진행할 수 없음
- trap 걸림 -> interrupt랑 비슷함
- 이때 trap handler routine에 따라서 kernel 안으로 들어감
- 세팅된 parameter들을 보고 어떤 이유로 trap이 걸렸는지 확인함
- 확인했으면 자기가 갖고 있는 kernel 내 function으로 신호 보냄
- 끝나면 user-mode로 되돌리고 interrupted location으로 return
-> 이게 system call

- kernel이 I/O를 대신해줄 때 permission을 체크함
- permission보고 만족하면 해주고 아니면 안 해줌
- ex)
1) 어떤 program이 disk sector에 대해서 write를 해달라고 요청함
2) kernel이 그 disk sector에 대해서 program이 write permission이 있는지 확인
3) 있으면 해 주고 없으면 안 해줌

1) compile 된 파일이 chmodk를 실행시키면 trap이 걸림
2) trap이 걸리고 kernel mode 바뀜
3) kernel 안에 있는 trap의 trap handler가 왜 trap 걸렸는지 확인하고 적당한 function으로 보내줌
4) permission check 하고 맞는 거 실행시켜줌
5) 끝나면 user mode 바뀜
6) return
-> system call 과정에서 kernel function에 접근해야 되니 왜 kernel 이 항상 memory resident인지 알 수 있음
system call에서 어떤 kernel function을 부를지 모르니 memory에 항상 있어야됨

- main memory에서 보면 이렇게 됨

- program은 local variable이나 sfp(saved frame pointer)나 ret(return addresss) 같은 것들이 저장되는 stack이 필요함
- kernel function 호출 하고 local variable 같은 것도 쓰고 return도 하니까 kernel stack도 당연히 필요함
- stack 필요성) function call 했을 때 함수가 끝나면 필요 없는 local variable들을 저장할 memory 영역을 항상 할당해놓으면 memory 낭비라서

- 프로세스마다 할당받는 가상 메모리에서 위에 1GB Kernel 영역 안에 Kernel stack이 있는 것 같음

- 이런 식의 흐름
Invoking a system call
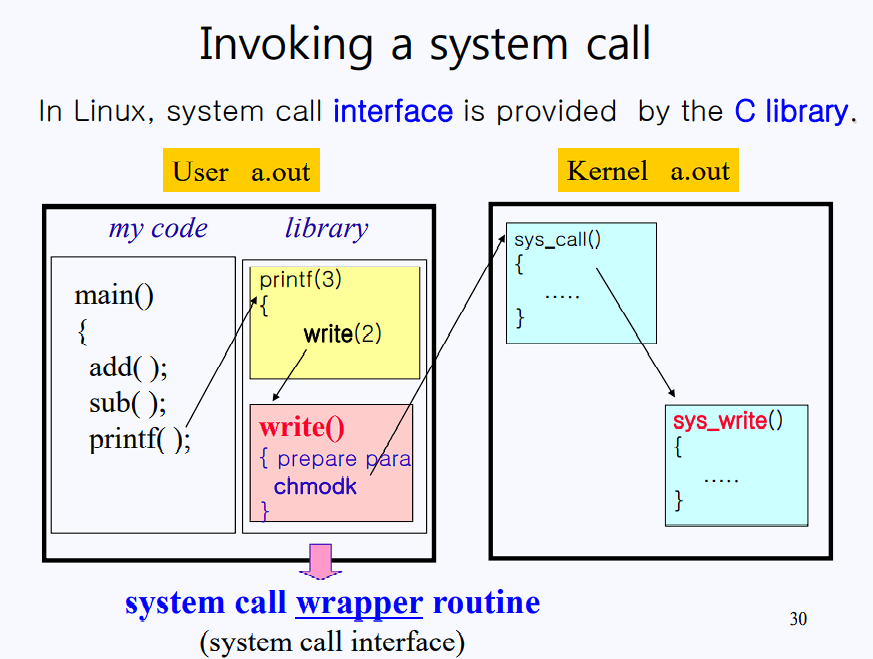
- printf ibrary function을 call 하면 그 library function 실행됨
- library function이 실행되다가 I/O를 해야 되면 wrapping 해주는 function call
- parameter를 미리 세팅해주고 chmodk를 해주는 function을 system call wrapper routine이라고 부름
- wrapper routine이 필요한 이유는 read 때문에 가는지, write 때문에 가는지 구분하고 필요한 parameter 전달하려고
- trap 걸려서 kernel이 받으면 받은 parameter 보고 적절한 function으로 보냄
- function 실행되고 리턴

- Wrapper routine안에서 보면 eax로 sys call number 세팅해주고 argument를 push 해줌
- 여기선 x86_32에서의 syscall을 예시로 보여줌
- x86_64는 interrupt 0x80 대신에 syscall 사용하고 레지스터에 넣어서 세팅함

- sys_call이 현재 process의 context save
- 앞에서 말한 trap handler임
- valid 검사
- eax에 들어간 sys call number를 sys_call에서 보고 나서 sys_call_table이라는 array를 참조해서 sys call number에 맞는 function의 start address를 받아서 실행
- 끝나면 return

- Naming convention은 sys_ + syscall name

- 만약 읽으면 kernel process가 요청한 process한테 읽은걸 줘야 됨
- 근데 그 둘은 독립적인 process임
- 그래도 kernel은 모든 memory access 가능
- user space로 데이터 가져오고 주는 게 가능함
- 당연히 user space에서 kernel space 건드는건 안됨

- sys call number는 Architecture 의존적이고 바뀔 수 없음
- syscall table은 kernel trap handler가 갖고 있음

- syscall을 맘대로 추가해버리면 platform dependent program들이 안 돌아갈 수 있음
- = 비효율적

- 새로운 file descriptor 만들어서 쓰라는 말
'OS, Kernel' 카테고리의 다른 글
| Kern Koh Kernel of Linux Interrupt 정리 (0) | 2022.08.06 |
|---|---|
| Kern Koh Kernel of Linux Scheduling 정리 (0) | 2022.07.20 |
| Kern Koh Kernel of Linux Process Management 정리 (0) | 2022.07.19 |
| Kern Koh Kernel of Linux Introduction 정리 (0) | 2022.07.18 |