CPU 기본 구조
CPU구조는 아키텍처마다 다 다르다. 표기법도 OS마다 약간씩 다르다.

CPU는 크게 CU(Control Unit), ALU(Arithmetic-Logic Unit), Register Set으로 나눌 수 있다.
ALU는 각종 산술 연산과 논리 연산을 수행하는 하드웨어 모듈이다.
Register set은 레지스터(register)의 집합이다.
레지스터는 CPU 내부의 기억 장치로서, CPU가 동작하면서 사용하는 기억장치이다. 기억 장치 중에 가장 액세스 속도가 빠르다.
CU는 프로그램 코드(명령어)를 해석하고 제어 신호를 발생시키는 하드웨어 모듈이다. ISA(Instruction Set Architecture)에 따라 구조가 달라진다.

ISA는 컴퓨터가 실행할 수 있는 명령의 집합이다.

CISC VS RISC
CISC(Complex Instruction Set Computer)와 RISC(Reduced Instruction Set Computer)가 있다.
CISC는 명령어 길이가 가변적이고 최소 크기의 메모리 구조를 가진다. 호환성이 좋다. 명령어가 복잡해서 명령어 해석에 오래 걸리고, 명령어 해석에 필요한 회로도 복잡하다. 명령어 길이가 고정되어 있지 않아서 명령을 실행하는데 단일 클럭 주기 이상이 소요될 수 있다. 그래서 pipelining이 어렵다.
CISC는 대표적으로 Intel사의 x86 CPU가 있다. 사실 순수 CISC라고 보기에는 어렵다. 그 이유는 x86이 내부적으로 RISC처럼 동작해서 pipelining을 할 수 있고 CISC 명령을 에뮬레이션 하는 형태를 취하고 있기 때문이다.
RISC는 명령어 길이가 16bit 32bit 이런 식으로 고정되어있다. 때문에 명령어 해석기가 단순화되었고 명령을 실행하는데 거의 단일 클럭 주기가 소요된다. pipelining이 쉽다.
하지만 코드 길이는 늘어나서 메모리에서 더 많은 공간을 차지한다.
대표적으로 MIPS 아키텍처가 있다.
Bus Interface는 입출력을 전달하는 통로이다. 서로 데이터를 주고받으려면 통로가 필요한데 그 통로의 역할을 한다.
CPU 동작 과정


위 사진들을 보면 PC(Program Counter), MAR(Memory Address Register), MBR(Memory Buffer Register), IR(Instruction Register), AC(Accumulator)들이 있다. 기본적으로 명령을 실행하기 위한 레지스터들이다.
실제 상용 CPU에서 물리적으로 존재하는 레지스터는 아니고 CPU의 동작을 설명하는데 사용되는 레지스터로 보면 된다.
PC는 다음턴에 어느 명령어를 가져와야 하는지에 대한 주소를 기억하고 있는 레지스터이다.
IR은 현재 실행중인 명령을 기억하는 레지스터이다.
AC는 연산 결과를 임시로 저장하는 레지스터이다. 오른쪽 사진에선 ACC로 표현하고 있다.
MAR은 데이터의 주소를 기억하는 레지스터이다.
MBR은 데이터를 임시로 저장하는 레지스터이다. 오른쪽 사진에선 MDR(Memory Data Register)로 표현되어있다.


CPU가 한 개의 명령어를 실행하는 데 필요한 전체 처리 과정을 명령어 사이클(instruction cycle)이라고 한다. Execution cycle이라고 부르기도 하는 것 같다.
기본적으로 IF(Instruction Fetch), ID(Instruction Decode), EX(instruction EXecution), MEM(MEMory), WB(Write Back) 5 stages로 구성된다. store은 memory와 write back 두 가지를 총칭하는 말이다. 4번째 단계를 Execution에 포함시켜서 3단계로 설명하기도 한다.
각 단계에는 하나의 클럭 사이클이 필요하다.
이 클럭 사이클은 하드웨어 이벤트가 발생하는 시점을 결정하는 클럭을 이용해서 만들어진다.
한 클럭 사이클에 걸리는 시간을 클럭 주기(clock period)라고 한다.
예를 들어 한 명령이 5 클럭 사이클이 걸린다고 하면 CPI(Cycles Per Instruction)는 5가 된다.
IF는 PC에 있는 주소를 통해 그 주소의 값을 가져와서 IR에 넣는 것이다. 즉 명령을 가져오는 것이다.
1) MAR에 PC가 담긴다.
2) MAR의 값이 Address Bus를 통해 메모리로 간다.
2) CU가 Control Bus를 통해 메모리에 Read Signal을 보낸다.
3) 값이 Data Bus를 통해 MDR(MBR)에 담긴다.
4) Instruction이기 때문에 IR에 MDR이 담긴다.
5) PC가 명령어 길이만큼 증가한다.
ID는 명령을 해석한다.


명령은 opcode(operation code)와 operand로 나뉜다.
메모리에서 가져온 opcode는 일반적으로 CU의 binary decoder에 의해 수행된다.
1) IR에 opcode부분이 Data Bus를 통해 CU로 간다.
2) CU가 opcode를 해석한다.
EX는 해석한 명령을 실행한다. 명령에 따라 동작이 달라진다.
CU가 해석한 명령에 따라 제어 신호를 ALU같은 CPU의 관련 기능 장치에 전달한다.
만약 명령에 산술 또는 논리가 포함되어있는 경우엔 ALU가 사용된다.
여기선 데이터를 읽어올때의 동작을 예시로 들었다.
1) IR의 operand 부분은 MAR에 담긴다.
2) MAR의 값은 Address Bus를 통해서 메모리에 간다.
3) CU가 Control Bus를 통해 메모리에 Read Signal을 보낸다.
4) 값이 Data Bus를 통해 MDR로 온다.
5) 명령이 아닌 데이터기 때문에 AC로 간다.
MEM: 데이터 메모리에 액세스해야 하는 경우 수행된다.
branch가 필요하면 PC를 destination address로 바꾼다.
딴 경우엔 그냥 스킵된다.
WB : 결과를 알맞은 레지스터에 쓴다.


MIPS 아키텍처로 명령이 처리되는 과정의 예시이다.
폰 노이만 아키텍처

폰 노이만 구조이다. 처음으로 stored-program의 개념이 도입되었으며, 전처럼 하드웨어를 재배치하지 않고 소프트웨어만 교체하면 되기 때문에 범용성이 향상되었다.
현재 거의 모든 컴퓨터들이 이 폰 노이만 구조를 따르고 있다.
이 구조의 단점으로 폰 노이만 병목 현상이 있다.
이 병목 현상은 컴퓨터 시스템 처리량이 최고 속도의 데이터 전송 속도에 비해 프로세서의 상대적 기능으로 인해 제한된다는 생각이다. 프로세서는 메모리에 액세스 하는 동안 idle 상태가 된다. 이를 해결하려고 메모리 계층 구조나, DMA, NUMA 같은 기술이 나왔다.
또한 내장 메모리 순차처리 방식으로 인해서 데이터 메모리와 프로그램 메모리가 구분되어 있지 않고 하나의 버스로 통신하는 구조라서 CPU는 명령어와 데이터에 동시에 접근하지 못한다. 그래서 나온 것이 하버드 아키텍처이다.
메모리 계층 구조


메모리 계층 구조를 보면 상위 계층일수록 용량은 작고, 속도는 빠르다.
하위 계층일수록 용량은 크고, 속도는 느리다.
레지스터가 가장 빠르고, CPU가 동작하면서 이 레지스터를 사용한다. 캐시 메모리와 같이 Flip Flop 구조를 가지고 있다. 하지만 더 가까이 붙어있어서 캐시보다 빠르다.
32/64비트 시스템이라 부르는 것이 이 레지스터의 크기를 나타내는 것이다.
한 번에 처리할 수 있는 데이터가 32비트가 되려면 32비트 크기의 레지스터를 가지고 있어야 하고 64비트의 경우도 64비트 레지스터를 가지고 있어야 64비트 데이터를 처리할 수 있다.
32비트의 경우에는 주소가 2^32 byte만큼을 표현해줄 수 있어서 약 4GB 정도의 메모리만 인식할 수 있다.


캐시는 일반적으로 Level1, Level2, Level3정도로만 분류한다.
L3로 갈수록 크기가 크고 L1으로 갈수록 크기가 작다.
데이터를 찾을 때, L1, L2, L3순서로 올라가면서 데이터를 찾는다.
L1이 제일 가까워서 당연히 더 빠르다.
요즘 CPU들은 다 캐시 메모리를 가지고 있고, 제조사들은 캐시 메모리가 많이 비싸기 때문에, 무턱대고 캐시 메모리를 올리지 않는다.

이 캐시가 효율적으로 동작하기 위해서는 필요한 데이터가 미리 잘 캐싱되어있어야 한다.
캐시는 데이터를 저장할 때 지역성을 고려해서 데이터를 저장한다.
지역성은 기억장치 내의 정보를 균일하게 액세스 하는 것이 아니라 어느 한순간에 특정 부분을 집중적으로 액세스 하는 특성이다.
지역성은 시간적 지역성과 공간적 지역성이 있다.
시간적 지역성은 최근의 참조된 주소의 내용이 다시 참조되는 특성이다.
공간적 지역성은 프로그램이 참조도니 주소와 인접한 주소의 내용이 다시 참조되는 특성이다.
캐시 메모리는 MMU(Memory Management Unit)에 의해서 관리된다.
MMU는 가상 주소를 물리 주소로 변환하고, 유저 영역과 커널 영역을 구분 관리하는 등의 메모리 접근 제어 역할도 한다.
MMU는 별도의 칩으로 된 경우도 있지만 통상적으로 CPU의 일부가 된다.
입출력 제어 방식



PIO(Programmed I/O)는 네트워크 어댑터나 ATA 기억 장치와 같은 주변 기기와 CPU 사이에 데이터를 주고받는 방식 중 하나이다. 원하는 I/O가 완료되었는지 여부를 검사하기 위해 CPU가 상태 플래그를 계속 확인하고 I/O가 완료되면 자료 전송을 CPU가 처리한다. 모든 데이터는 CPU를 통과해야만 한다. 때문에 I/O 작업 시 CPU는 다른 작업을 할 수 없다.
입력의 완료를 알리는 interrupt가 필요 없는 대신 계속 CPU가 확인해야 된다.

Interrupt I/O는 PIO의 단점을 해결하기 위해 나왔다. 데이터를 전송할 준비가 되면 I/O 인터페이스가 interrupt 신호를 CPU한테 보내서 CPU가 처리하도록 한다. flag 검사를 안 해도 된다. 그래서 PIO보다는 효율적이다. 하지만 모든 데이터가 프로세서를 통과하는 것은 똑같기 때문에 여전히 많은 시간을 소비한다.
DMA(Direct Memory Access)는 PIO와 대비대는 개념이다. Direct Memory Access라는 말 그대로의 의미를 가지고 있다.
CPU 개입 없이 DMA controller가 알아서 데이터 전송을 해준다. 그리고 끝나면 CPU에게 interrupt를 걸어서 알려준다.
그래서 프로세서는 전송의 시작과 끝에서만 개입을 해주면 된다.

NUMA(Non Uniform Memory Access) 아키텍처는 간단하게 프로세서와 메모리가 한 세트를 이루는 것을 의미한다.
프로세서와 메모리 한 세트를 Numa Node라고 부른다. Bus로 각각의 Node가 연결되어있다. 각 프로세서가 독립적인 지역 메모리 공간을 가지고 있어서 빠른 메모리 접근이 가능하다. 모든 프로세서가 로컬 메모리에 동시 접근이 가능해서 병목 현상이 발생하지 않는다. 하지만 로컬 메모리가 아닌 다른 프로세서의 메모리에 접근할 경우 링크를 통해 접근해야 돼서 시간이 소요되어 성능 저하가 발생한다.
폰 노이만 아키텍처 VS 하버드 아키텍처


하버드 아키텍처는 폰 노이만 아키텍처와 다르게 메모리가 분할되어있다.
보다시피 하버드 아키텍처에서는 명령과 데이터를 둘 다 동시에 읽을 수 있다.
병렬 처리가 가능한 대신 당연히 전기 회로는 더 필요하다.
수정된 하버드 아키텍처

하버드 구조를 캐시 메모리에 적용했고, 폰 노이만 구조를 CPU 외부(주 메모리)에 적용하였다.
최근 CPU의 성능이 메모리 속도와 비교해 크게 향상되었다. 그래서 성능을 높이기 위해 주 메모리의 접근 횟수를 줄이는 노력이 필요하다. 명령을 처리할 때마다 주 메모리에 접근할 필요가 있다면 성능 향상을 전망할 수 없다. 이른바 메모리 속박 문제이다.
메모리는 속도가 올라가면 값이 비싸진다. 그래서 이를 해결하기 이해서 캐시로 불리는 작은 규모의 고속 메모리를 사용한다. 캐시 메모리는 위에 메모리 계층 구조에 나와있다.
CPU는 필요로 하는 메모리의 내용이 캐시에 존재하면 성능이 향상된다. 만약 필요한 메모리의 내용이 캐시에 없으면 메모리로부터 캐시로 내용을 가져온다.
이 수정된 하버드 아키텍처는 최근 CPU들에게 적용된다.

사실 좀 오래되긴 했지만, 펜티엄도 보면 Data Cache와 Code Cache를 나눠놓았다.
Pipelining

MIPS를 예시로 들었다. RISC라서 pipelining에 용이하다.
x86에 경우에는 일단은 CISC라서 바로 pipelining을 하면 문제가 생길 수 있다. 왜냐하면 명령어의 길이가 일정하지 않고 복잡해서 Data Dependency 때문에 pipelining이 힘들다. 그래서 인텔은 x86 명령을 디코딩하고 micro-operations로 변환해서 1사이클에 1 코드 실행을 가능하게 했다.
이 구조를 보면 IF, ID, EX, MEM, WB를 처리하는 부분이 나뉘어있는 것을 볼 수 있다.
만약 Sequential Execution을 하면 명령이 돌면서 필요한 구성 요소만 쓰이고 나머지는 idle상태이다.
Pipelined Execution을 하면 모든 구성 요소들이 쉬지 않고 일을 할 수 있다.
명령들은 각각의 해당하는 functional unit에 의해서 실행된다.
IF/ID, ID/EX, EX/MEM, MEM/WB는 pipeline register로 단계를 분리하고 후속 pipeline 단계에서 필요한 정보를 필요한 단계까지 전달하는 데 사용된다.
여기서 Memory는 메모리와 통신하는 회로를 가리킨다.
Register File은 위에서 언급한 Register Set정도로 보면 된다.

MEM 부분을 보면 MUX(MUltipleXer)가 있다. 이 MUX는 jump나 branch 명령일 가능성이 있을 수 있어서 다시 PC에 넣어줘야 할 수도 있기 때문에 존재한다.

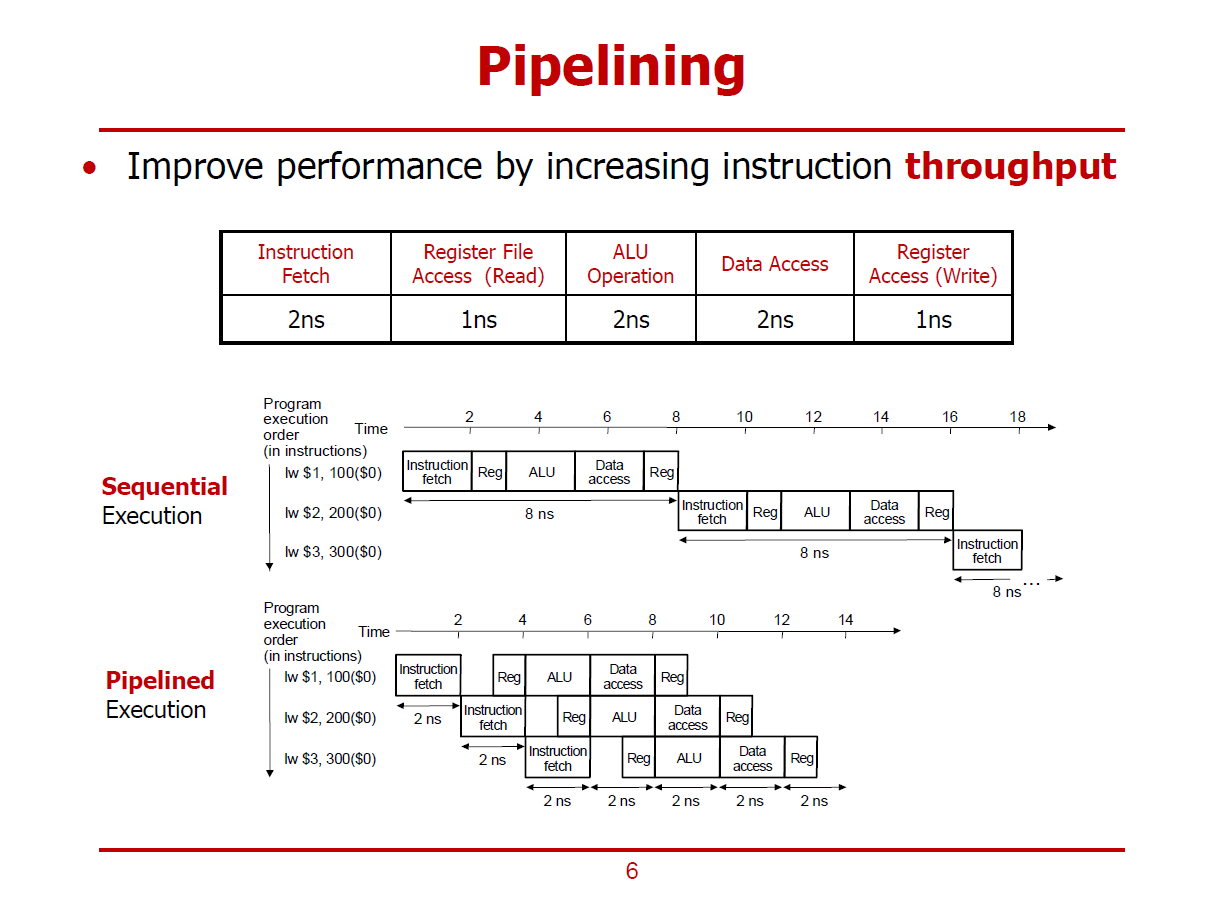
위는 pipeline이 적용된 Pipelined Execution이고 아래는 Sequential Execution이다.
레지스터가 반갈죽난 이유는 레지스터가 빨라서 한 클럭 신호안에서 두 번을 동작할 수 있어서 그렇다.

예시는 MIPS 5-stage로 가져왔지만 CPU마다 pipeline stage의 수는 다르다.
펜티엄 4 프레스캇은 31단계의 pipeline stage를 가지고 있었다.
결론적으로 pipeline은 instruction의 처리 속도를 높이는 것이 아니라 한 번에 처리할 수 있는 instruction의 수(stage)를 늘려서 throughput을 늘리는 것이라고 볼 수 있다.
pipeline도 한계가 있다. 이것을 Pipeline Hazards라고 한다.
Pipeline Hazards
Structural hazards, Data hazards와 Control hazards(Branch hazards)로 나뉜다.
Structural hazards는 같은 클럭 사이클에 실행하기 원하는 명령어의 조합을 하드웨어가 지원할 수 없다는 것을 의미한다.
즉 경쟁하는 명령들이 둘 다 같은 자원을 요구하는 상태이다.
위에 MIPS 아키텍처를 보면 IF와 MEM에서 둘 다 메모리에 액세스 해야 한다. 또한 Register Fetch와 Write Back도 둘 다 레지스터를 참조하는 것이다.
혹은 처리가 늦는 경우도 해당한다.
Pipeline stall로 해결하거나 자원을 더 추가하면 된다.
클래식 RISC pipeline은 하드웨어를 복제해서 이 문제를 피했다.
branch 명령의 경우엔 branch를 위한 ALU를 따로 설계했다.
우리의 pipelined processor는 이게 일어날 일이 없다. (충분한 자원이 있기 때문)
Data hazards는 어떤 명령이 이전 명령에 종속성을 가질 때를 말한다.
- RAW (Read After Write) dependency
- WAW (Write After Write) dependency
- WAR (Write After Read) dependency


이런 경우들이 있겠다. 해결 방법은 Pipeline stall(Pipeline bubble)이나 Forwarding(Bypassing)이 있다.

Pipeline stall은 그냥 stall 하는 거다.

Forwarding이 가능한 이유는 ALU에서 나온 결과를 파이프라인 레지스터에 저장하고 따른 ALU로 바이패싱해줄 수 있기 때문이다. 바이패싱된 값은 포워딩 유닛에 의해서 제어 신호가 전달돼서 ALU에 인자로 들어가는 입구에서 MUX로 선택지를 준다.

위와 같은 방식은 하드웨어적으로 개선하기 위한 방안이고, 개발자나 컴파일러가 ASM에선 nop 같은 걸로 처리하기도 한다. 이런 걸 Code Scheduling이라고 한다.
Control hazard는 branch나 jump 같은 것들 때문에 생긴다.
branch condition이 계산되기 전까지는, 다음 명령어의 fetch를 수행할 수 없게 되는 상황을 의미한다.
즉 조건에 따라서 다음에 실행될 명령어를 모르기 때문에 발생한다.
해결하는 방법은 Pipeline Stall, Delayed Branch, Branch prediction 등이 있다.
Pipeline Stall은 branch direction이 명확해질 때까지 stall 하는 걸 뜻한다. 앞에서 말한 거랑 똑같다.
pipeline stage만큼 stall 해야 되는데 성능 터진다.
Delayed Branch는 NOP를 삽입해서 처음부터 Branch hazard가 발생하지 않도록 하는 방법이다.
branch 여부와 관계없이 다음 명령어 실행을 방지하기 위해 NOP를 넣는다.

이 NOP를 사용하면 딜레이가 발생하니 NOP자리에 dependency가 없는 다른 명령을 채워 넣자는 취지에서 나온 것이 delay slot scheduling이다.
branch 전에 independent 한 instruction이 있으면 slot에 채워 넣는다.
Branch prediction

Branch prediction은 말 그대로 예측하는 거다. 기존 stall 방식보다 효율적으로 처리할 수 있다.
예측이 맞으면 낭비 없이 계속 잘 구르는 거고 틀리면 flush 돼서 pipeline stages만큼 낭비된다.
Branch prediction(Direction prediction)에는 여러 가지 방법들이 있다. 크게 Static branch prediction과 Dynamic branch prediction으로 나눌 수 있다.

Static branch prediction에는 Predict Branch Not Taken(Always not taken)과, Predict Branch Taken(Always taken), BTFN(Backward taken forward not taken)등이 있다. 정해진 규칙에 따라 실행 전에 branch를 미리 정하는 것이다. 컴파일 타임에 돌아간다.
Predict Branch Not Taken은 branch가 수행되지 않을 것이라고 미리 예측하는 방식이다.
MIPS에선 평균적으로 47%의 branches가 not taken 된다. 바로 다음 명령어가 이미 계산될 수 있다. MIPS 명령은 32비트 니까 PC+4하면 된다. 예측 실패하면 여전히 control hazard가 발생한다.
Predict Branch Taken 방식은 branch가 수행될 것이라고 미리 예측하는 방식이다.
다음 수행될 명령의 target address를 모르기 때문에 여전히 1 사이클의 페널티가 존재한다.
MIPS에선 평균적으로 53%의 branches가 taken된다. 예측이 틀리면 control hazard가 여전히 발생한다.
BTFN(Backward taken forward not taken) backward-going branches는 taken 되고 forward-going branch는 not taken 된다.
Dynamic branch prediction은 Static branch prediction보다 대체로 정확도가 높다. 실행 중 정보를 활용해서 branch prediction을 수행한다. 런타임에 돌아간다. Last time prediction이나 Two-bit counter based prediction 등이 있다.
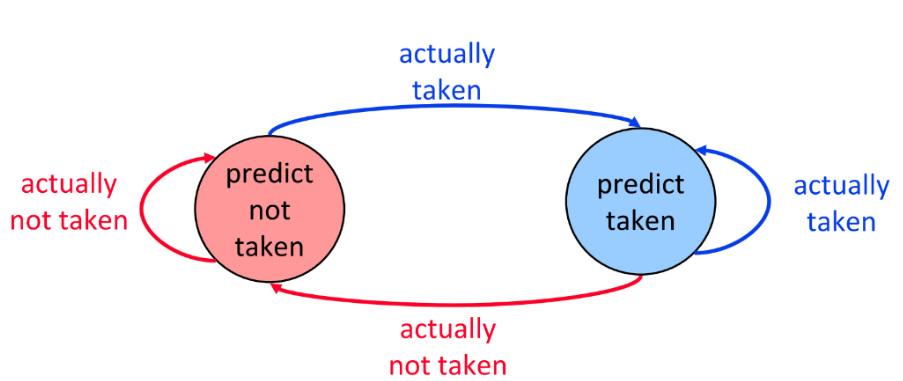
Last time prediction은 1bit짜리 BTB(Branch Target Buffer)를 사용한 prediction으로 마지막 결과를 따라 한다. 만약 10101010101010 branch가 있으면 다 틀린다.

Two-bit counter based prediction은 2bit짜리로 바꿔서 확률을 높인 거다. 두 번 연속으로 틀렸을 때만 바꿔서 확률을 높였다. 80에서 90%까지 나와서 꽤 많이 사용하는 방식이다.
Speculation execution(Speculative execution)
성능을 위해 다음 실행될 명령어를 예측해서 미리 실행하는 기법이다.
Branch prediction이후에 branch가 사용되는지 여부를 예측하고 그 예측된 branch부터 명령이 실행되어야 하는지 모르니 Speculation execution을 한다. 만약 branch가 제대로 예측되었다면 non-speculative가 되고 예측이 틀렸다면 speculative execution의 결과는 throw 되고 제대로 된 branch부터 실행한다.
Out-of-order execution
Out-of-order execution은 말 그대로 비순차적으로 실행시키는 것을 뜻한다.
실행 효율을 높이려고 순서에 따라 처리하지 않는 기법이며 수많은 프로세서들이 이 기법을 채용하고 있다.
pipeline에서 forwarding 등으로 dependency가 해결되지 않으면 stall 하는데 그걸 해결하기 위해서 out-of-order execution을 사용한다. 컴파일러단에서도 scheduling을 해줄 수도 있지만, 컴파일러는 microarchitecture에 관여할 수 없고, 결국은 ISA에만 관여한다는 한계가 존재한다. 이는 런타임에 간접적으로만 영향을 줄 수 있다는 것을 시사한다.
전에 배웠던 일반적인 pipelining은 statically scheduled pipelines 혹은 inorder pipelines라고 한다. 말 그대로 순서가 있는 pipelining이다. 즉 program order에 따라 명령이 실행된다.
ld r1, 0(r2) // load r1 from memory at r2
add r2, r1, r3 // r2 := r1 + r3
add r4, r3, r5 // r4 := r3 + r5r3와 r5는 register file에 준비되어있다고 가정한다. 만약 load 명령이 L1 cache에서 누락된다면 load unit은 L2 cache에서 데이터를 다시 로드하는데 몇 사이클이 더 소요된다. 그러면 이 시간 동안 pipeline은 stall 된다.
그런데 두 번째 add 명령은 r1에 dependency가 없다. 그래서 issue 되고 execute 될 수 있다. 하지만 inorder pipeline에서는 이게 stall 때문에 실행이 안된다. out-of-order execution은 이 idle 시간을 dependency가 없는 두 번째 add 명령어로 때운다.
덕분에 cache miss 같은 예측 불가능한 지연이 있어도 대응이 가능하고, 컴파일 타임에 의존성을 알 수 없는 경우에도 효율적으로 실행할 수 있다.
'Layer7 동아리 과제' 카테고리의 다른 글
| 리버싱 2차시 과제 (0) | 2022.07.20 |
|---|---|
| 하드웨어 3, 4차시 과제 (0) | 2022.06.19 |
| 하드웨어 1차시 과제 (0) | 2022.06.08 |
| 웹 해킹 8차시 과제 (0) | 2022.05.25 |
| 웹 해킹 7차시 과제 (0) | 2022.05.22 |